JS Kodu Çalıştırmak İçin Nasıl Bir Yol İzleyeyim ?
-
selamlar
python/java ile yazılmış bir uygulamam var. java kısmı içinde JS çalıştırmam gerekiyor. şöyle ki:
kullanıcıya basit matematik işlemleri yapabilmesi için js kodu girebilecğei bi alan verdim. bu alanda kullanıcıdan aldığım JS yi veritabanındaki her kayıt için çalıştırmam gerekiyor.
örneğin adam diyo ki : fiyat alanını : "fiyat * 18.5 + ' EUR'" yap. benim gidip her satir icin bunu calistirmam lazim vs vs.
şimdiye kadar bunu mongodb nin içindeki JS interpreter la yaptım , iş görüyor ama satır sayısı artınca cortluyor.
Java da script manager diye bir dalga var ama onun da boot olması uzun sürüyor.
bir web app kurup http üstünden istek atsam mantıklı olur mu sizce? 4 cpu 16 gb ramli bi aletle 10 milyon isteği kaç dakikadar karşılayabilirim mesela? (yarın denicem bunu tabi).
ya da başka bir fikriniz var mıdır?
-
merhaba. python olsaydı veriyi çekip pandas, dask veya duckdb ile manipule et derdim. benzer şekilde ayrı bir program yazıp, java'dan buraya mesaj gönderip javascript'i evaluate edip dönebilirsin. bunu hızlandırmak için kafka veya rabbitmq gibi bir mesaj broker'ı üzerinden yapabilir ve bu programı dağıtık yapabilirsin. ayrıca kayıtları tek tek değil grup halinde gönderip, grup halinde cevapları dönebilirsin. https://thingsboard.io/docs/pe/reference/msa/#javascript-executor-microservices bu uygulamada senin dediğine benzer şekilde çalışan bir rule engine var. değerleri manipule etmek için node.js uygulaması yazmışlar. aklıma gelenler bunlar, umarım fikir vermek açısından faydalı olmuştur.
-
ZoRKaYa bunu yazdı
merhaba. python olsaydı veriyi çekip pandas, dask veya duckdb ile manipule et derdim. benzer şekilde ayrı bir program yazıp, java'dan buraya mesaj gönderip javascript'i evaluate edip dönebilirsin. bunu hızlandırmak için kafka veya rabbitmq gibi bir mesaj broker'ı üzerinden yapabilir ve bu programı dağıtık yapabilirsin. ayrıca kayıtları tek tek değil grup halinde gönderip, grup halinde cevapları dönebilirsin. https://thingsboard.io/docs/pe/reference/msa/#javascript-executor-microservices bu uygulamada senin dediğine benzer şekilde çalışan bir rule engine var. değerleri manipule etmek için node.js uygulaması yazmışlar. aklıma gelenler bunlar, umarım fikir vermek açısından faydalı olmuştur.
eyvallah hocam,
pythondaki libler veri büyüyünce sıçıyorlar. denedik hepsini. baya patates çıktılar. şu an 240gb ram, 60 cpu lu makinada çalışan bi python kodum var. 70-80 dakikada tamamlıyor işi. bunu javada yazmaya başladım. aynı işi benim 8 core / 16 ramli laptopta 3.5 dakikada falan yapıyor :)
ben de en son senle aynı şeyi düşündüm ya. bi tane web app yazayım node da, request body den aldığı text i eval yapıp geri döndürsün sadece :P
google a "fastest nodejs framework" yazdım bu çıktı : https://www.fastify.io/
denicem yarın bi zorlayıp.
ama bu da çok salakça bi çözümmüş gibi geliyor niyeyse xd daha makul bişey olması gerekiyor gibi duruyor.
bi de şimdi şunu gördüm belki bu da işime yarar : https://duktape.org/ bunu deneyeceğim bi de.
belki bilmediğim bişey vardır.
yolbulucu tarafından 17/Ara/22 01:50 tarihinde düzenlenmiştir -
yolbulucu bunu yazdıZoRKaYa bunu yazdı
merhaba. python olsaydı veriyi çekip pandas, dask veya duckdb ile manipule et derdim. benzer şekilde ayrı bir program yazıp, java'dan buraya mesaj gönderip javascript'i evaluate edip dönebilirsin. bunu hızlandırmak için kafka veya rabbitmq gibi bir mesaj broker'ı üzerinden yapabilir ve bu programı dağıtık yapabilirsin. ayrıca kayıtları tek tek değil grup halinde gönderip, grup halinde cevapları dönebilirsin. https://thingsboard.io/docs/pe/reference/msa/#javascript-executor-microservices bu uygulamada senin dediğine benzer şekilde çalışan bir rule engine var. değerleri manipule etmek için node.js uygulaması yazmışlar. aklıma gelenler bunlar, umarım fikir vermek açısından faydalı olmuştur.
eyvallah hocam,
pythondaki libler veri büyüyünce sıçıyorlar. denedik hepsini. baya patates çıktılar. şu an 240gb ram, 60 cpu lu makinada çalışan bi python kodum var. 70-80 dakikada tamamlıyor işi. bunu javada yazmaya başladım. aynı işi benim 8 core / 16 ramli laptopta 3.5 dakikada falan yapıyor :)
ben de en son senle aynı şeyi düşündüm ya. bi tane web app yazayım node da, request body den aldığı text i eval yapıp geri döndürsün sadece :P
google a "fastest nodejs framework" yazdım bu çıktı : https://www.fastify.io/
denicem yarın bi zorlayıp.
ama bu da çok salakça bi çözümmüş gibi geliyor niyeyse xd daha makul bişey olması gerekiyor gibi duruyor.
bi de şimdi şunu gördüm belki bu da işime yarar : https://duktape.org/ bunu deneyeceğim bi de.
belki bilmediğim bişey vardır.
hocam 240 gb ram ve 60 cpu'lu makineyle, senin java'da 3.5 dakikada yaptığın iş 20 saniyede yapılır, ne yaptın sen. nasıl 70-80 dk'da çalışıyor, veri ne büyüklükte, dağıtık mı, hesaplamada partition gerekiyor mu yoksa row-based mi? şimdi pandas'ta iterrows yapıp satır satır yaparsan başka, apply yaparsan başka, dask'la paralel computation yaptırırsan başka, spark'la cluster'da yaparsan bambaşka. önemli olan kod yazmak değil, anlayarak yazmak. günümüz dünyasında saniyenin altında işlem yapmayacaksan, dillerin de pek önemi kalmadı artık.
-
ZoRKaYa bunu yazdıyolbulucu bunu yazdıZoRKaYa bunu yazdı
merhaba. python olsaydı veriyi çekip pandas, dask veya duckdb ile manipule et derdim. benzer şekilde ayrı bir program yazıp, java'dan buraya mesaj gönderip javascript'i evaluate edip dönebilirsin. bunu hızlandırmak için kafka veya rabbitmq gibi bir mesaj broker'ı üzerinden yapabilir ve bu programı dağıtık yapabilirsin. ayrıca kayıtları tek tek değil grup halinde gönderip, grup halinde cevapları dönebilirsin. https://thingsboard.io/docs/pe/reference/msa/#javascript-executor-microservices bu uygulamada senin dediğine benzer şekilde çalışan bir rule engine var. değerleri manipule etmek için node.js uygulaması yazmışlar. aklıma gelenler bunlar, umarım fikir vermek açısından faydalı olmuştur.
eyvallah hocam,
pythondaki libler veri büyüyünce sıçıyorlar. denedik hepsini. baya patates çıktılar. şu an 240gb ram, 60 cpu lu makinada çalışan bi python kodum var. 70-80 dakikada tamamlıyor işi. bunu javada yazmaya başladım. aynı işi benim 8 core / 16 ramli laptopta 3.5 dakikada falan yapıyor :)
ben de en son senle aynı şeyi düşündüm ya. bi tane web app yazayım node da, request body den aldığı text i eval yapıp geri döndürsün sadece :P
google a "fastest nodejs framework" yazdım bu çıktı : https://www.fastify.io/
denicem yarın bi zorlayıp.
ama bu da çok salakça bi çözümmüş gibi geliyor niyeyse xd daha makul bişey olması gerekiyor gibi duruyor.
bi de şimdi şunu gördüm belki bu da işime yarar : https://duktape.org/ bunu deneyeceğim bi de.
belki bilmediğim bişey vardır.
hocam 240 gb ram ve 60 cpu'lu makineyle, senin java'da 3.5 dakikada yaptığın iş 20 saniyede yapılır, ne yaptın sen. nasıl 70-80 dk'da çalışıyor, veri ne büyüklükte, dağıtık mı, hesaplamada partition gerekiyor mu yoksa row-based mi? şimdi pandas'ta iterrows yapıp satır satır yaparsan başka, apply yaparsan başka, dask'la paralel computation yaptırırsan başka, spark'la cluster'da yaparsan bambaşka. önemli olan kod yazmak değil, anlayarak yazmak. günümüz dünyasında saniyenin altında işlem yapmayacaksan, dillerin de pek önemi kalmadı artık.
apache spark kullaniyorum pyspark ile beraber. 10gb (8 milyon satır) + 1gb(15 milyon satır) + ufak tefek 300-500 mb lık dosyalar var. bunlar sql deki gibi joinleyip satır bazında 20-30 tane işlem yapıyorum üstünde. joinlemek dışındaki bütün işlemlerin row based.
pythonda önerilen her çözümü denedim. dataframe tabanlı libler apply tarzı bişey yaptığımda tüm datayı rame almaya çalışıyor illa. bu da baya uzatıyor işi sanırım.
pyspark kullanırken biraz scalayı gördüm, sonra scaladaki parallel collectionsu gördüm. baktım aynısı javada da varmış. bi deniyim dedim. resmen sihir gibi geldi. kara büyü amk.
java stream 100-150mb rami geçmeden baya hızlı çözdü işimi. veriyi hiç rame almadan satır satır okuyup işleyebiliyorum. javada implement edene kadar iş görülsün diye devasa bi makine açtım işte ben de :D
edit: şu an şöyle bir flow kurdum kendime: joinleri spark ta yapıyorum (pyspark değil, direkt spark-shell le yaptırıyorum.) 4-5 dakika sürüyor joinlemek. (javada join kısmını yazmaya uğraşmamak için).
sonra veriyi java da streamle okuyup zibilyon tane işlem yaptırıyorum ve yazıyorum bir yerlere. anladığım kadarıyla javadaki bottleneckim disk oluyor, ramdisk yaratıp bi tane ramdiskten okuyup ramdiske yazmayı planlıyorum.
yolbulucu tarafından 17/Ara/22 02:14 tarihinde düzenlenmiştir -
@ZoRKaYa sen bilgili bi abiye benziyorsun , bana çok hızlı veri yazıp okuyabileceğim şemasız bir db önerir misin? mongodb sıçıyor ya veri büyüyünce. cassandra kullanacaktım ama şema oluşturmam lazım. gelecek verinin şekli konusunda bir bilgim yok. bu yüzden şema yaratmak çok zor geldi.
-
hocam kafana göre mongodb seceyim cassandra seceyim demek dogru degil.
NoSql'in kendi yapisi var. Tipik iliskisel veritabanlari ACID prensibine göre calisir. NoSql cözümleri ise CAP teoremine göre göre calisir. Bir noSql cözümü en fazla iki harfi kapsar. Yani piyasada olan cözümler genelde CA, CP ya da AP seklinde ayrilir. Bu 3 seklin de kullanim yerleri farklidir. O yüzden CAP teoremini okuyup, ona göre bir cözüm secmek gerek.
Bu tablo ne kadar dogru bilmem (üreticilerin sitesini okumak gerek), MongoDB C ve P yi kapsiyor. Cassandra ise A ve P yi.

senin veri yapini bilmiyorum, ancak noSQL de belli basli türler var. En bilinen tabi mongodb document olarak tutuyor, ama neo4j ya da gremlin graph tabanli tutuyor
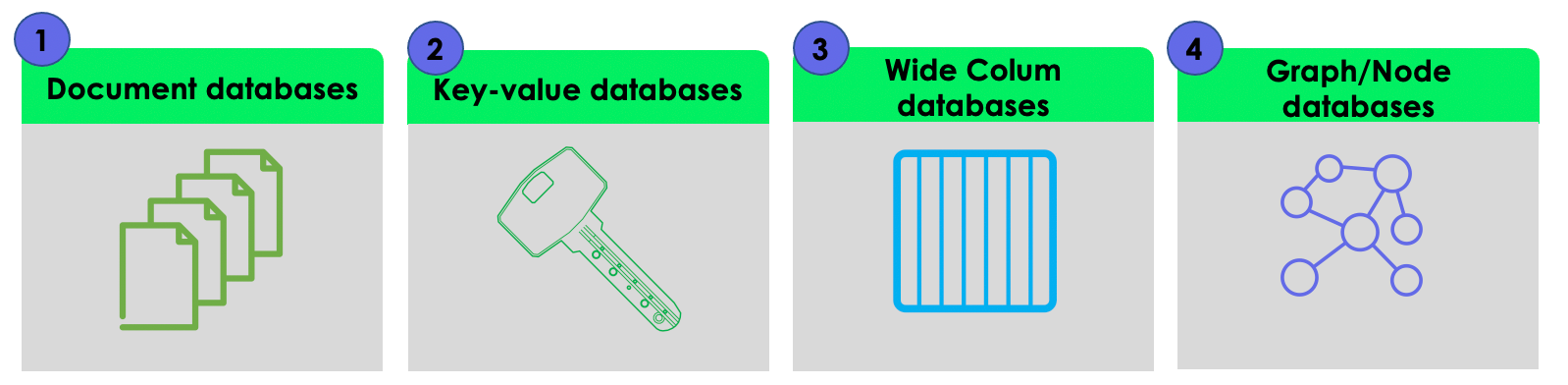
CAP'e göre dogru sistemi secikten sonra, burdan uygun saklama bicimini secmen gerek. Mesela key-value tipi yetiyorsa onlara bakacaksin mesela DynamoDB, ya da json tabanli bir seyler saklayacaksan document tabanli, birbirleriyle iliskili nodelar varsa o zaman graph, tipik sütunlar olsun diyorsan da column based dblere bakacaksin.
Eger memory tabanli bir sey isini görürse Redis ya da memcache'e bakabilirsin. (redis bildigim kadariyla db olarak da kullanilabiliyor yani verileri kaydedebiliyorsun ama hic o sekil kullanmadim ve datayi key-value olarak tutuyorsun)
Hatta azure'un nosql ile ilgili cesitleri var ve cok büyük datalari isleyebilirler. Onlari inceleyebilirsin (ancak pahali olur)
döküman tabanli olarak da Couchbase server'i inceleyebilirsin. Eski calistigim firmada kullaniyorlardi.
bunlar genel tanimlardi..
sorundan anladigim kadariyla, en kolay güncelleme yapma olayina bakiyorsan, bence document tabanli bir yapi yerine, key-value ile güncellemelerin daha basit olacagini ve hizli olacagini düsünüyorum. O yüzden key-value cözümlerini incelemek mantikli görünüyor.
JS'yi icten distan nasil cailstirirsin onu bilmiyorum.
Edit: Son olarak eger para sorun degilse, azure'un data servisleri cidden iyi. Eger http request yapma imkanin varsa js ile falan ugrasmana da gerek kalmaz. Startup'lar icin kredi vs de veriyor ama tabi ben azure'u pahali buluyorum
unbalanced tarafından 17/Ara/22 03:48 tarihinde düzenlenmiştir -
unbalanced hocam çok güzel detaylı cevaplamış aslında, ben de hızlı yazmak ve okumak dediğin anda daha önce kullandığım HBase ve Redis geldi aklıma. Bunlar in-memory olduğu için gerçekten çok hızlılar fakat senin dediğin türde daha sonra her satır üzerinde gezeyim ve datayı update edeyim şeklinde değiller. Veriyi key-value şeklinde saklar hızlıca aradığını bulur getirir, üzerinde işlemini yaparsın. Datayı çok hızlı şekilde okuyayım ve biryerlerde kaydedeyim, kaybolmasın şeklinde kullanımı olur. Kafka da aynı şekilde consistency level ayarlarlanarak distributed bir şekilde veri kaybının önüne geçmek için kullanılabilir. Eğer gelen verilerin her birisi farklı alanlara sahip json objeleriyse, mecbur document-oriented bir veri tabanı tercih etmek gerekli. Verinşn yapısını ve kullanıcı ihtiyaçlarını bilmeden tasarım yapmak çok zor. Örneğin; gelecek verilerin tipini belirtecek bir identifier varsa (mesela araç plakası ve sensör tipi) ona göre birden fazla veritabanı kombine şekilde (araç plakası ve sensör tipinin sahip olduğu alanlar RDBMs'te kaydedilir, <araç_plakası>_<sensor_tipi>_<alan_adı_1> şeklinde bir key ile key-value DB'de sensör bilgileri kaydedilir) bile kullanılabilir. Eğer bütün verileri manipule edip yeniden hesaplamana gerek yoksa, sadece gösterilecek veriye js kodu uygulanabilir. Ama güncelleme yapıp güncellenmiş veriyi kaydedeyim diyorsan Apache storm veya nifi gibi bir yapıyla yukarıda bahsettiğim gibi sadece belirli tipteki sensörlerin verilerini güncelleyip (100'le çarpmak) başka bir key ile yine db'ye kaydetmek gibi bir çözüm de mümkün. Çok güzel ve heyecan verici çalışma alanları, başarılar.
-
yolbulucu bunu yazdı
eyvallah hocam,
pythondaki libler veri büyüyünce sıçıyorlar. denedik hepsini. baya patates çıktılar. şu an 240gb ram, 60 cpu lu makinada çalışan bi python kodum var. 70-80 dakikada tamamlıyor işi. bunu javada yazmaya başladım. aynı işi benim 8 core / 16 ramli laptopta 3.5 dakikada falan yapıyor :)
1- Hangi PY sürümü çalışıyor serverda
2- Veri boyutu-derinliği nedir
-
unbalanced bunu yazdı
hocam kafana göre mongodb seceyim cassandra seceyim demek dogru degil.
NoSql'in kendi yapisi var. Tipik iliskisel veritabanlari ACID prensibine göre calisir. NoSql cözümleri ise CAP teoremine göre göre calisir. Bir noSql cözümü en fazla iki harfi kapsar. Yani piyasada olan cözümler genelde CA, CP ya da AP seklinde ayrilir. Bu 3 seklin de kullanim yerleri farklidir. O yüzden CAP teoremini okuyup, ona göre bir cözüm secmek gerek.
Bu tablo ne kadar dogru bilmem (üreticilerin sitesini okumak gerek), MongoDB C ve P yi kapsiyor. Cassandra ise A ve P yi.
senin veri yapini bilmiyorum, ancak noSQL de belli basli türler var. En bilinen tabi mongodb document olarak tutuyor, ama neo4j ya da gremlin graph tabanli tutuyor
CAP'e göre dogru sistemi secikten sonra, burdan uygun saklama bicimini secmen gerek. Mesela key-value tipi yetiyorsa onlara bakacaksin mesela DynamoDB, ya da json tabanli bir seyler saklayacaksan document tabanli, birbirleriyle iliskili nodelar varsa o zaman graph, tipik sütunlar olsun diyorsan da column based dblere bakacaksin.
Eger memory tabanli bir sey isini görürse Redis ya da memcache'e bakabilirsin. (redis bildigim kadariyla db olarak da kullanilabiliyor yani verileri kaydedebiliyorsun ama hic o sekil kullanmadim ve datayi key-value olarak tutuyorsun)
Hatta azure'un nosql ile ilgili cesitleri var ve cok büyük datalari isleyebilirler. Onlari inceleyebilirsin (ancak pahali olur)
döküman tabanli olarak da Couchbase server'i inceleyebilirsin. Eski calistigim firmada kullaniyorlardi.
bunlar genel tanimlardi..
sorundan anladigim kadariyla, en kolay güncelleme yapma olayina bakiyorsan, bence document tabanli bir yapi yerine, key-value ile güncellemelerin daha basit olacagini ve hizli olacagini düsünüyorum. O yüzden key-value cözümlerini incelemek mantikli görünüyor.
JS'yi icten distan nasil cailstirirsin onu bilmiyorum.
Edit: Son olarak eger para sorun degilse, azure'un data servisleri cidden iyi. Eger http request yapma imkanin varsa js ile falan ugrasmana da gerek kalmaz. Startup'lar icin kredi vs de veriyor ama tabi ben azure'u pahali buluyorum
unbalanced reyizzz yine bir sürü şey yazmışın, eyvallahhh ! :)
abi şimdi cap teorem falan güzel diyon da benim hızlıca veri yazabilmem lazım. ve key-value işimi görmüyor, elimdeki şeyler document. bu verileri de bulk olarak yazıp sonra bulk olarak okuyabilmem lazım.
normalde bi dosyaya yazıp ordan okuyabilirim ama kullanıcıya bu veriler üstünde preview yapma özelliği vermem gerekiyor, bu da pagination gerektiriyor. diskteki dosyayı açıp seek etmek uzun süren bir şey
ilişkidir bilmemnedir hiç işim yok. db de yapacağım 3-5 işlem var : "al kardeş şu 1 milyon satırı sakla" "bana 50-150 arasındaki satırları ver" , "bana tüm veriyi ver bişey yapcam" , "o tabloyu sil al tüm bu veriyi geri yaz" . bu kadar.
http request atabilirim ama neye request atmayı kastettiğini, bunun neyi çözeceğini anlamadım. para sorun değil genel olarak, işimi görecek herhangi bi platforma para ödeyebilirim.
-
selam
simdi hocam aslinda mongodb 10 milyon vs problem degil ama belki bu kullandigin js interpreter sorun yaratiyor olabilir.
Simdi aklima gelenleri yazayim
1- Eger sadece fiyat kismi güncellenecekse, o kismi key-value icinde tutup, kalan kisimlari document'de tutabilirsin. Ancak bu sekilde 2 farkli db kullanman gerekiyor ve onlari gösterirken de birlestirebilirsin
2- mongodb'yi azure'da kullanabilirsin hocam. Sen bu js olayini söyle yapabilirsin. Azure functions diye bir olay var, burada yazigin kod ile db'ye erisim saglayabilirsin ve bildigim kadariyla ikisi ayni makinede calisabilir. Böylece hem hizli olur hem de http requestle azure function'i tetiklersin ve azure function da db'de update yapar
3- ayrica yine azure da cesitli data toollar var hocam. Data factory'de pagination olayi var. üstte verdigim column based, document based, graph based ve key-value olarak tutan cözümleri mevcut. Yeni data girislerini, normalizasyon olayini vs hep yapabilirsin (bir pipeline kurararak)
4- ravendb diye bir nosql cözümü var. Ancak bu cözüm bir nosql olmasina ragmen, CAP yerine, ACID prensibiyle calisiyor. Real-time icin cok iyi yani hizli okuma yazma islemi mümkün. (rabbitmq ya da kafka kullanabilirsin). ETL kullaniyor (extract, transform, load) bu da hiz konusunda önemli zaten. Ve senin icin en önemlisi document tabanli tutuyor. Istersen bir incele https://ravendb.net/
suan aklima gelenler bunlar
unbalanced tarafından 17/Ara/22 13:29 tarihinde düzenlenmiştir



